Warning: mysql_result() expects parameter 1 to be resource, boolean given in /var/www/cyberdyn/html/stats/stats_ro.php on line 2
Vizitator nr. din 14/10/2010 Vizitatori @nline: 1 Membrii @nline: 0
Ultima actualizare:
|
INFRASTRUCTURĂ: HPCC - Benchmark
Infrastructură Cibernetică pentru Studii Geodinamice Relaționate cu Zona Seismogenică Vrancea
Sistemul HPCC/HPVC este bazat pe noile servere Dell PowerEdge R815 cu 4 CPU cu 12 coruri (AMD 2.0 GHz) si 96-128 GB RAM. Pentru a putea testa performanta rularilor in paralel pe un astfel de sistem, trebuie sa rulam coduri numerice paralelizate cu OpenMP sau Matlab.
Pana acum au fost rulate benchmark-uri pentru coduri paralelizate cu softurile OpenMP, Matlab si CitcomS:
Test OpenMP pe un nod de calcul DellR815 cu 48 de coruri si 128GB RAM
OpenMP (Open Multi-Processing) este un API (Application Programming Interface) multiplatforma care suporta programare multiprocesor cu memorie impartita in C, C++ si Fortran pe majoritatea arhitecturilor de procesot si pentru sisteme de operare gen Linux. OpenMP este diferit de OpenMPI, care este folosit pentru programare multiprocesor cu memorie distribuita si care se poate scala pe sute si mii de procesoare.
Testul realizat reprezinta o aplicatie pentru multiplicare de matrici, in care s-a folosit gcc4.1.2 pentru compilarea codului. S-au folosit 12, 24, 36 si 48 de coruri iar rezultatele se pot vedea mai jos:
|
|
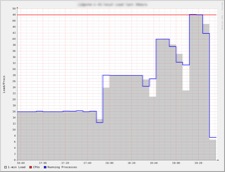
Gradul de folosire al procesorului pentru nodul de calcul 001 in timpul multiplicarii paralelizate a unei matrici. Axa verticala reprezinta numarul de coruri. Axa horizontala reprezinta timpul de calcul. Observati cum timpul de calcul scade pe masura cresterii numarului de coruri.
|
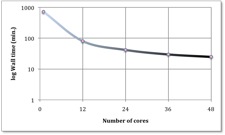
Timpul de executie vs. numarul de coruri. Axa verticala are scara logaritmica.
|
Test MatLab, Parallel Computing Toolbox and Distributed Computing Server pe CyberDyn
MATLAB reprezinta un limbaj de inalt nivel si un mediu interactiv ce asigura posibilitatea de calcul intens mult mai rapid decat prin folosirea limbajelor traditionale de programare cum ar fi C, C++ si Fortran. MatLab are doua instrumente principale pentru realizarea calculelor paralele: Parallel Computing Toolbox (PCT) si Distributed Computing Server (DCS). PCT permite rezolvarea problemelor solicitante atat ca volum de date cat si ca volum de calcul folosind procesoare multicore, GPU si clustere. Aplicatiile MATLAB pot fi paralelizate fara a folosi programare CUDA sau MPI. DCS permite rezolvare problemelor prin executarea aplicatiilor MATLAB pe un cluster (doar daca PCT este instalat). Se pot rula aplicatii paralele fie interactiv fie in batch.
Testul realizat reprezinta o aplicatie pentru calcularea numarului pi prin metoda Monte-Carlo (serial si paralel). S-au folosit 1, 2, 4 si 8 de coruri iar rezultatele se pot vedea mai jos:
|
| Number of Workers |
Wall time (sec.) |
| 1 |
1488 |
| 2 |
795 |
| 4 |
409 |
| 8 |
204 |
|
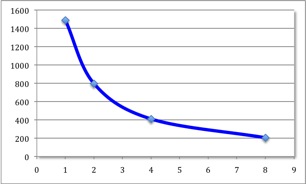
Se poate observa o crestere a vitezei de calcul in functie de numarul de workers (coruri). Folosind un cod serial pentru un worker, codul are nevoie de 25 de minute pentru a termina. Folosind acelasi cod, dar paralelizat pentru 8 workeri, codul are nevoie de doar 3 minute.
|
Test CitcomS (pachet de programe paralelizate FEM) test pe Cyberdyn
CitcomS este un cod de elemente finite scris in C, ce rezolva convectia termo-chimica pentru o calota sferica. Poate rezolva probleme atat pentru regiuni restranse cat si pentru intregul domeniu sferic. Cu toate ca acest cod poate sa rezolve diferite probleme de convectie folosin flexibilitatea data de elementele finite, exista unele aspecte ale CitcomS-ului care il fac sa fie extrem de util pentru rezolvarea problemelor in care intervin scenariile de paleoreconstructie. Este posibila includerea si varierea diversilor parametri, cum ar fi: vascozitatea, inclusiv a celei dependente de temperatura, presiune, pozitie, compozitie si stress.
A/In cele ce urmeaza vom prezenta rezultatele unui test in care se foloseste un model regional ce se intinde in suprafata pe 1x1 radiani, iar in adancime, de la suprafata pana la limita nucleu-manta. Am folosit cateva rezolutii pentru model, de la 17x17x9 noduri pana la 257x257x129 noduri de elemente finite (sau 400 km x 400 km x 438 km pana la 25 km x 25 km x 27 km) si un numar crescator de nuclee de calcul, de la 4 la 1024 procesoare.
Se pot trage cateva concluzii importante: pentru modele cu rezolutii joase (17x17x9 sau 33x33x17 noduri FEM), timpul minim de calcul este obtinut folosind 16-32 noduri de calcul. Folosind un numar mai mare de procesoare, timpul de calcul va creste datorita retelei de comunicatii intre nodurile de calcul. Oricum, pentru modele cu rezolutie inalta (129x129x65 sau 257x257x129 noduri FEM), codurile de elemente finite scaleaza foarte bine, intervalul de timp scazand continuu, de la cateva zile (pentru 4 nuclee) la cateva ore (pentru 1024 de noduri de calcul).
|
|
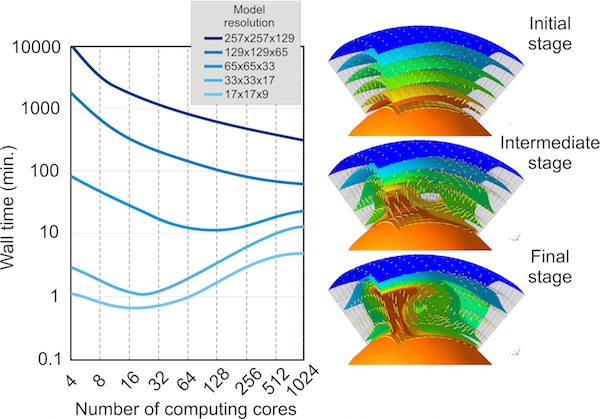
Testul benchmark folosind un model regional CitcomS. In stanga: testul de performanta folosind o rezolutie gradual crescatoare a retelei. In dreapta: cele trei etape succesive pentru modelul regional de convectie in manta. Suprafetele de aceeasi valoare, colorate reprezinta diferite izoterme. Sagetile galbene descriu curgerea in model. Sfera portocalie de la baza modelului reprezinta nucleul fierbinte al Pamantului. Modelele regionale au fost graficate folosind OpenDX.
|
B/Acesta este un alt test realizat prin utilizarea CitcomS, dar in acest caz am folosit un model complet sferic pentru rezolvarea unei probleme de convectie pur termica. Versiunea complet sferica a lui CitcomS a fost gandita pentru a putea rula pe un claster ce poate imparti domeniul sferic in 12 calote egale si apoi distribui calculele pentru calote pe procesoare separate. Am folosit cateva rezolutii, de la 9x9x9 noduri la 129x129x129 noduri FEM si de la 12 (12 calote x 1 x 1 x 1) la 768 (12 calote x 4 x 4 x 4) noduri de calcul.
Se pot trage cateva concluzii importante: pentru modele cu rezolutii joase (9x9x9 sau 17x17x17 noduri FEM), timpul minim de calcul este obtinut folosind 24-96 noduri de calcul. Folosind un numar mai mare de procesoare, timpul de calcul va creste datorita retelei de comunicatii intre nodurile de calcul. Oricum, pentru modele cu rezolutie inalta (adica 129x129x129 noduri FEM), codurile de elemente finite scaleaza foarte bine, intervalul de timp scazand continuu, de la cateva zile (pentru 24 nuclee) la cateva ore (pentru 768 de noduri de calcul).
|
|
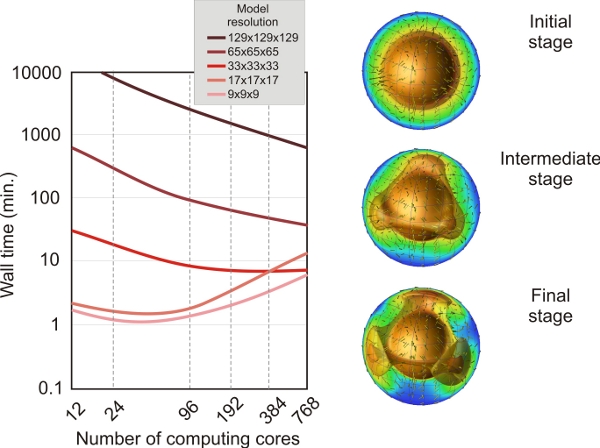
Testul benchmark folosind un model complet sferic CitcomS. In stanga: testul de performanta folosind o rezolutie gradual crescatoare a retelei si un numar crescator de noduri de calcul. In dreapta: cele trei etape succesive ale modelului. Suprafetele de aceeasi valoare, colorate, repreznta diferite izoterme. Sagetile galbene descriu curgerea in model. Sfera portocalie de la baza modelului reprezinta nucleul fierbinte al Pamantului. Modelele regionale au fost graficate folosind OpenDX.
|
C/Acesta este un benchmark mai complex in care utilizam CitcomS cu un model complet sferic pentru rezolvarea unei probleme de convectie termo-chimica in care anomaliile de densitate datorate heterogeneitatilor compozitionale si termice determina realizarea curgerii convective. Versiunea complet sferica a lui CitcomS a fost gandita pentru a putea rula pe un claster ce poate imparti domeniul sferic in 12 calote egale si apoi distribui calculele pentru calote pe procesoare separate. Codul foloseste trasori pentru a putea identifica traiectul particulelor cu o anumita compozitie chimica in interiorul Pamantului. Am folosit un numar de 20 de trasori pe element finit. Am folosit cateva rezolutii, de la 9x9x9 noduri la 129x129x129 noduri FEM si de la 12 (12 calote x 1 x 1 x 1) la 768 (12 calote x 4 x 4 x 4) noduri de calcul. numarul de trasori variaza de la peste 6000 pentru modelele de rezolutie joasa, la peste 25 de milioane pentru modelele de rezolutie inalta.
Se pot trage cateva concluzii importante: pentru modele cu rezolutii joase (9x9x9 sau 17x17x17 noduri FEM), timpul minim de calcul este obtinut folosind 12-24 noduri de calcul. Folosind un numar mai mare de procesoare, timpul de calcul va creste datorita retelei de comunicatii intre nodurile de calcul. Pe de alta parte, pentru modelele de inalta rezolutie (adica 33x33x33 sau 65x65x65 noduri FEM), intervalul de timp scad continuu de la cateva zile (pentru 12 nuclee) la cateva zile atunci cand sunt folosite 768 noduri de calcul. Oricum, pentru modele cu rezolutie inalta (adica 129x129x129 noduri FEM si peste 25 de milioane de trasori), intervalul de timp minim este obtinut atunci cand folosim 384 noduri de calcul. Folosind mai multe nuclee (adica 768), intervalul de timp creste de la cateva ora la mai mult de o zi.
|
|
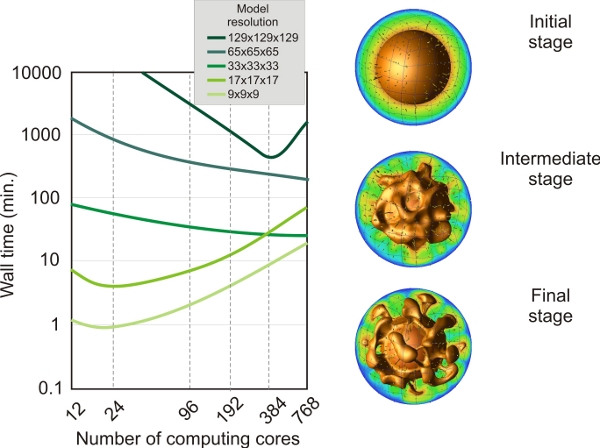
Testul benchmark folosind un model complet sferic CitcomS pentru rezolvarea problemei de convectie termo-chimica. In stanga: testul de performanta folosind o rezolutie gradual crescatoare a retelei si un numar crescator de noduri de calcul. In dreapta: cele trei etape succesive ale modelului. Suprafetele de aceeasi valoare, colorate, repreznta diferite izoterme (0.8 pentru temperatura adimensionala). Sagetile galbene descriu curgerea in model. Sfera portocalie de la baza modelului reprezinta nucleul fierbinte al Pamantului. Modelele regionale au fost graficate folosind OpenDX.
|
|


